Where Do LLMs Learn From: Training Data Analysis
Where Do LLMs Learn From: Training Data Analysis
Breakdown of GPT-3's training data sources and their relative proportions
GPT-3: The Foundation of Modern LLMs
Where do these large language models get their knowledge? Let's analyze the new datasets used by OpenAI's GPT-3, which marked the beginning of the LLM revolution.
Core Training Sources:
-
1
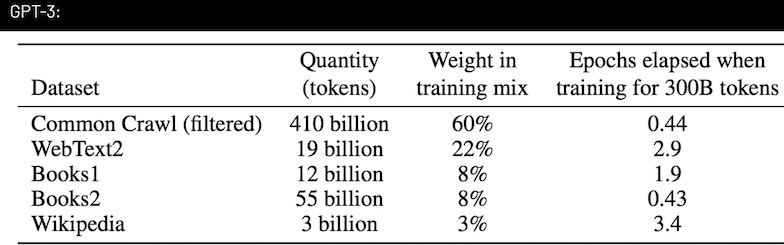
Common Crawl (60%)
- Largest source:
60%of training data - Monthly-updated snapshot of the Internet
- Contains
400+ billion tokens(≈ 6 million books)
- Largest source:
-
2
WebText2 (22%)
- Based on Reddit-curated content
- 15 years of upvoted links
- High-quality, human-filtered content
-
3
Additional Sources
- Books and Wikipedia articles
- Structured, verified information
Evolution of Training Data

Major Publishers
News CorpAxel SpringerTIMEThe AtlanticThe Wall Street JournalFinancial Times
Online Platforms
Reddit- Community discussionsStack Overflow- Technical knowledgeShutterstock- Visual content
Impact on Search and SEO
Key Implications
- Quality standards are rising as models learn from verified sources
- Technical accuracy is increasingly important due to specialized dataset inclusion
- Community engagement may influence content value in training sets
- Visual content description is becoming more relevant
Future Implications
- Growing importance of authoritative content
- Increased value of technical accuracy
- Rising significance of community engagement
- Enhanced combining of multimedia content
Stay Connected
- Visit AI Search Watch
- Follow on LinkedIn
- Subscribe to newsletter
Part of "The Future of SEO in the Age of AI-Driven Search" series.
References
- Language Models are Few-Shot Learners - OpenAI
- Language Models are Few-Shot Learners - arXiv Paper
- OpenAI Destroyed AI Training Datasets - Business Insider
- OpenWebText2 Background Documentation
- OpenAI News Corp Licensing Deal - AI Business
- OpenAI's Training Data Partnerships - Fast Company
- Overview of OpenAI Partnerships - Originality.ai
Frequently Asked Questions
1. Where does GPT-3 get most of its training data from?
GPT-3 primarily gets its data from Common Crawl, which is roughly 60% of its training set.
2. Why is Common Crawl so important for large language models?
Common Crawl provides a vast, regularly updated snapshot of the web, offering varied text sources to improve language coverage and model performance.
3. What role does Reddit play in GPT-3’s training data?
Reddit content, primarily curated via the WebText2 dataset, provides high-quality, human-filtered text from upvoted links.
4. Do publishers like News Corp or TIME influence LLM training?
Yes. Partnerships with major publishers supply verified news and articles, raising the quality and authority of the training data.
5. How do books and Wikipedia articles fit into GPT-3’s dataset?
They add structured, well-edited sources of information, which improve factual accuracy and area coverage.
6. What are the impacts of these data sources on SEO?
Models increasingly prioritize reliable sources, meaning authoritative content and strong technical accuracy help with visibility in AI-driven search results.
7. Does GPT-3 include images in its training data?
GPT-3 itself focuses on text. But related models use image datasets, and references to visual content (like Shutterstock) are noted for multimodal systems.
8. Why is technical accuracy important in LLM training?
Accurate technical data boosts model credibility, reduces hallucinations, and improves responses in specialized fields.
9. Does community engagement affect the content used in training?
Yes. Highly engaged communities, like Reddit or Stack Overflow, produce valuable text that is more likely to be included in training sets due to its popularity and quality.
10. Are licensing deals with publishers needed for future AI training?
Licensing deals help make sure high-quality, authorized data, supporting both legal compliance and better training outcomes for advanced AI models.
11. How do language models evolve their training data over time?
They incorporate updates from web crawls, newly published texts, and official partnerships, leading to continuous refinement of their knowledge base.
12. What future trends can we expect in LLM training data?
We can expect more partnerships for authoritative data, tighter quality controls, and increased inclusion of community-driven and multimedia content.