Understanding Common Crawl: The Internet's Archive
Table of Contents
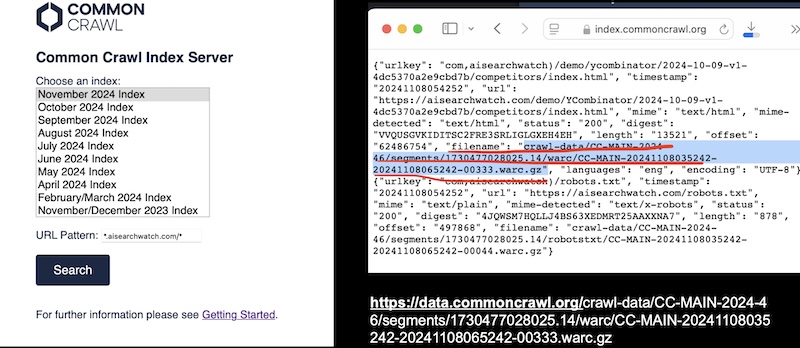
What is Common Crawl? It's this MASSIVE dataset that AI models use for training. Basically it's run by this nonprofit in California that goes around collecting and indexing data from all over the internet. They update their dataset every month which is pretty cool. If you're curious about your own website, you can actually search for it at index.commoncrawl.org.
Btw if you're into AI search engines (which you probably are if you're reading this), definitely check out our article on AI search engines. Those things are powered by this data!
So what can you do on that Common Crawl site? Lots of stuff actually:
- Search for your website (I looked up aisearchwatch.com cuz why not)
- See which pages they've captured
- Download data about your site
- Check which exact pages were crawled
- Look at your robots.txt file and see if they followed the rules
What is Common Crawl?
Common Crawl is seriously one of the biggest resources in AI development right now. As I mentioned, it's a nonprofit org that systematically collects and indexes data from basically everywhere online. They update monthly and AI developers use this as the foundation for training their models.
The Scale and Scope
Common Crawl's importance can't be overstated - it comprises approximately 60% of the training data used in new AI models like GPT-3. To put this in perspective, the Common Crawl dataset contains over 410 billion tokens of data, equivalent to the content of roughly 6 million books. This massive scale provides AI systems with a broad understanding of human knowledge and language patterns.
Accessing and Understanding Common Crawl
Content creators and developers can interact with Common Crawl data through several methods:
Index Search
At index.commoncrawl.org, users can:
- Search for specific websites within the index
- View captured pages and their content
- Access detailed crawl information
- Download relevant datasets for analysis
Examining Your Website's Presence
When you search for your website in Common Crawl, you can find:
- Which specific pages have been captured
- When these captures occurred
- How your content appears in the dataset
- What metadata is associated with your pages
Series Navigation
Previous Article: Where Do LLMs Learn From: Training Data Analysis
Next Article: Optimizing Content for AI Search Engines
Stay Connected
- Visit AI Search Watch
- Follow on LinkedIn
- Subscribe to newsletter
Part of "The Future of SEO in the Age of AI-Driven Search" series.
References
- https://index.commoncrawl.org/
- https://www.commoncrawl.org/
Frequently Asked Questions
1. What is Common Crawl, in simple terms?
Common Crawl is a nonprofit initiative that systematically collects and indexes massive amounts of web pages. It provides openly accessible, large-scale datasets used extensively in AI training and research.
2. How frequently is Common Crawl updated?
Common Crawl generally updates its datasets on a monthly basis, continuously expanding its archive of online content.
3. Why is Common Crawl significant for AI training?
Common Crawl offers a broad and varied snapshot of web content that helps AI models learn language patterns, context, and a vast range of topics, making it foundational for large-scale language models and search engines.
4. How do I check if my website is indexed by Common Crawl?
You can visit index.commoncrawl.org and search for your area name. The index will show you which pages of your site have been captured and the specific crawl data available.
5. Can I remove or block my website from the Common Crawl index?
Yes, you can use robots.txt directives to disallow crawling of certain pages or your entire site. But once data is already archived, removal requests might need to be directed to Common Crawl. Always refer to their documentation for the latest procedures.
6. How do AI search engines use Common Crawl data?
AI search engines use Common Crawl data as a core component to train language models. This helps them better understand user queries, context, and relevant content across the web.
7. Is it safe to rely on Common Crawl for SEO strategy?
While Common Crawl offers insight into how AI models see your site, it’s best to use it alongside other analytics tools (Google Search Console, SEO software) to shape a complete SEO strategy.
8. How can I analyze my website’s data in Common Crawl?
You can download and parse the publicly available WARC files or use Common Crawl’s index search. This will allow you to examine how your content appears in the dataset, including metadata and link structures.
9. Does Common Crawl respect robots.txt?
Common Crawl honors standard robots.txt directives to exclude or limit the crawling of certain pages. It’s always recommended to keep your robots.txt file up to date if you want to control how your site is crawled.
10. Are there any limitations or known issues with Common Crawl's dataset?
Common Crawl data may contain duplicates or outdated snapshots of web pages. It also might not cover 100% of the internet, so cross-verifying with other data sources is advisable.
11. Can I contribute or volunteer for Common Crawl?
Yes. Common Crawl is a nonprofit that encourages community support. Check their official website for donation links, contributing code, or volunteering to help improve tools and resources.
12. How can Common Crawl shape the future of SEO?
By offering a massive, open-access dataset for AI training and web indexing, Common Crawl can influence how search engines evolve. As AI-driven search matures, understanding and optimizing for these large-scale datasets will become increasingly important.
About The Author

Ayodesk Publishing Team led by Eugene Mi
Expert editorial collective at Ayodesk, directed by Eugene Mi, a seasoned software industry professional with deep expertise in AI and business automation. We create content that empowers businesses to harness AI technologies for competitive advantage and operational transformation.
Continue Reading:
MacBook Pro M5 vs M4 Pro vs MacBook Air M4 for Developers
Comparing the new MacBook Pro M5 14-inch with M4 Pro and MacBook Air M4 for development work, Docker...
AI Growth Strategy for a Small Vegan Deli
Step‑by‑step guide that shows how one vegan deli uses ChatGPT and other AI tools to boost reach, sal...
ChatGPT for Plastic Surgery Blogs: Fast Patient Education Content
Step‑by‑step guide for plastic surgeons using ChatGPT to create patient education blogs that answer ...